Introdução
Esta unidade vai proporcionar, a você, uma contextualização sobre Big Data Science no Brasil e no mundo. Isso vai permitir que tenha uma visão mais crítica de forma que ao atuar na área identificará os diferentes pontos abordados aqui.
Ademais, você vai poder aprender os principais conceitos mencionados em Big Data Science. Mais especificamente, vai conhecer o conceito de banco de dados, Big Data, Data Science, Machine Learning, além de conhecer também os principais instrumentos usados em Big Data Science. Bons estudos!
Objetivo específicos de aprendizagem
- Contextualizar a Big Data Science.
- Conhecer a definição de Data Literacy.
- Conhecer os principais conceitos em Big Data Science.
1. Contextualização da Big Data Science
Atualmente, são vários os dispositivos e sistemas que têm proporcionado uma quantidade enorme de dados. Atente-se para a imagem a seguir, a qual traz uma reportagem sobre os dados de Tecnologia da Informação.
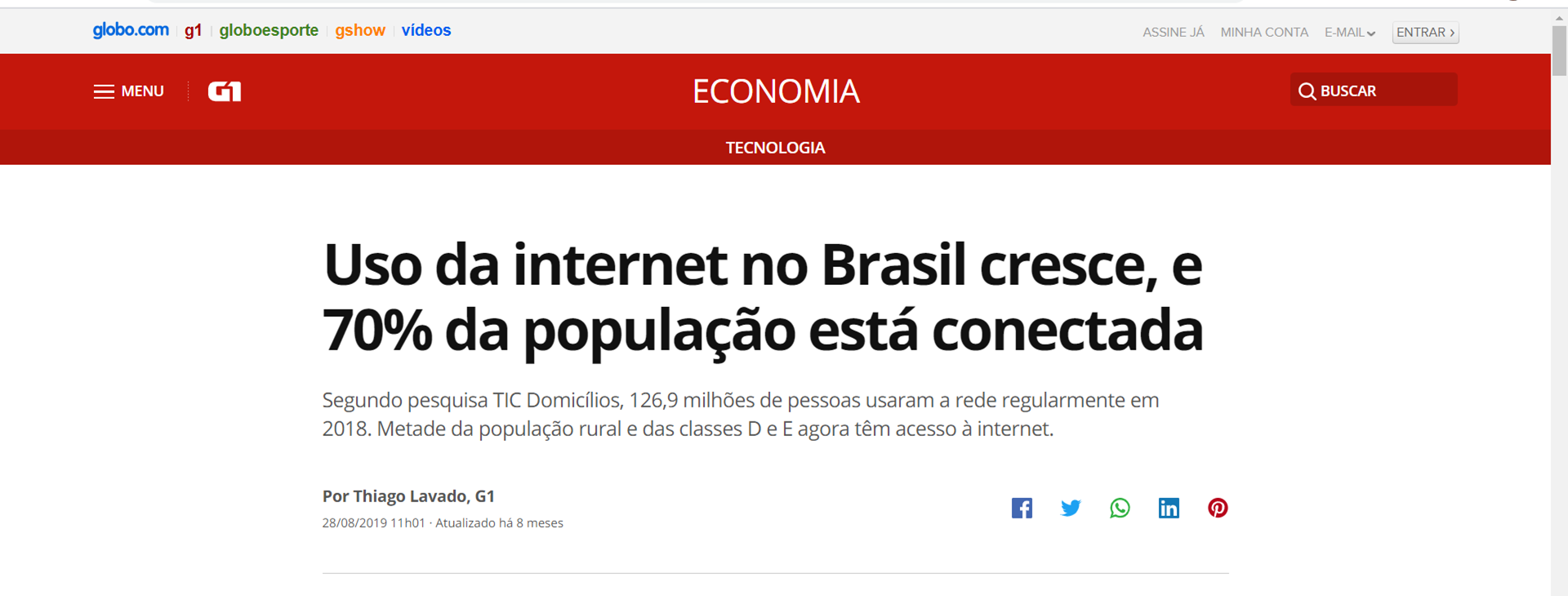
Fonte: Portal G1, 2019.
Disponível em: https://g1.globo.com/economia/tecnologia/noticia/2019/08/28/uso-da-internet-no-brasil-cresce-e-70percent-da-populacao-esta-conectada.ghtml. Acesso em 22 mai. 2022.
A imagem apresenta uma reportagem para demonstrar o uso crescente de internet entre os brasileiros intitulada como “Uso da internet no Brasil cresce, e 70% da população está conectada”.
Ainda na mesma reportagem, há um infográfico sobre os usuários da internet no Brasil.
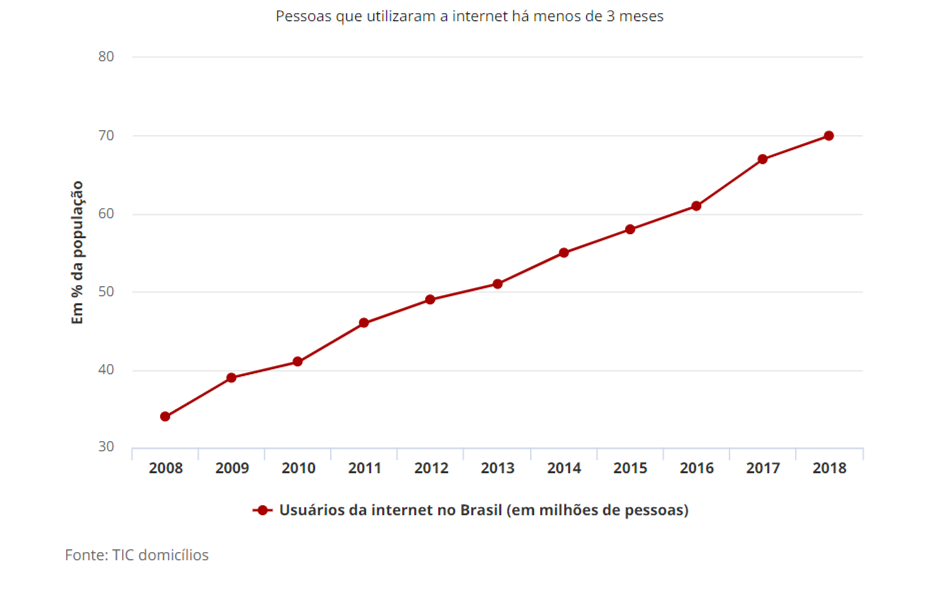
Fonte: Portal G1, 2019.
Disponível em: https://g1.globo.com/economia/tecnologia/noticia/2019/08/28/uso-da-internet-no-brasil-cresce-e-70percent-da-populacao-esta-conectada.ghtml, Acesso em 22 mai. 2022.
A imagem apresenta um gráfico com os usuários de internet no Brasil de 2008 até 2018 por meio de uma linha vermelha crescente.
Os números da figura a seguir, indicam que as mídias sociais como o Youtube, Facebook, Twitter, Instagram tem o seu uso cada vez maior e isso significa um volume e uma variedade maior de dados, a qualaumenta absurdamente a cada dia.

Fonte: Site EdiscoveryToday.
Disponível em: https://ediscoverytoday.com/2021/04/16/here-is-your-2021-internet-minute-infographic-ediscovery-trends/. Acesso em 23 mai. 2022.
A imagem apresenta um gráfico com o que ocorre na internet em um minuto em 2021.
Agora, vamos estudar a evolução da Big data Science no mundo e no Brasil. Vamos lá!
1.1 Evolução da Big Data Science no Mundo
Vamos estudar a evolução de Big Data. A Google começou com a criação de tecnologias como o MapReduce que permitiram de maneira consistente o processamento pesado e massivo com escala linear e baixo custo que ajudou a quebrar o paradigma muito limitado que se tinha até então. Agora a ideia era viabilizar o processamento que era muito limitado.

Fonte: Plataforma Delinea (2022)
a imagem representa um conjunto de tecnologias atuais, como computador, banco de dados, nuvem, celulares, tablets, entre outros exemplos.
No início dos anos 2000, o Yahoo era muito maior do que o Google e tinha uma necessidade muito parecida. Então o Yahoo estruturou uma equipe bem grande e organizada para começar a colocar em prática o que encontraram em um artigo publicado, na época, pelo Google.
Atenção
O Yahoo, então, começou a desenvolver uma tecnologia denominada Hadoop e depois para a comunidade Apache e nunca mais parou de evoluir a partir daí.
Hadoop basicamente é uma estrutura de software que é aberta (open-source) e é usada para armazenar e executar operações em clusteres de hardwares simples. O Hadoop também permite um armazenamento massivo para dados com poder de processamento consistente.

Fonte: Plataforma Delinea (2022)
a imagem representa um ser humano totalmente conectado à tecnologia.
Esse tipo de tecnologia também era uma necessidade de empresas como o Facebook e Ebay e, então, começaram a adotar o Hadoop logo em seguida. Isso aconteceu aproximadamente em 2007 e 2008. Desse modo, o Hadoop começou a se integrar com outros softwares e se tornou um ecossistema que nunca mais parou de evoluir, bem como se tornou um ecossistema integrado com outras soluções.
Para o processamento de banco de dados, foi preciso desenvolver algo também. Você imagina a situação: temos aplicativos de transporte como a Uber ou de streaming de vídeo como é o caso da Netflix. Esses dados são recebidos e transmitidos a todo instante e tem uma carga de dados bem elevada.
Nesse sentido, a escala de usuários e dados acaba gerando necessidades que o Standard Query Language (SQL) não atende. Por exemplo, temos o MongoDB e vários outros que foram sendo criados com a motivação de resolver esta situação e surgiu ainda o Sparkle que começou em 2009 e que se integrou com o Hadoop.

Fonte: Plataforma Delinea (2022)
a imagem representa a inovação na forma de pensar das pessoas.
Entre os anos de 2010 e 2020, tivemos uma evolução muito grande da parte open source já que houve uma maturidade nesse sentido. Então o open-source foi para soluções das empresas.
O mercado aceitou o open-source e inclusive não é mais um ponto de discussão. É um ponto fechado usar open-source em uma organização. Sobre a curva de aprendizado, tivemos um crescimento muito grande dos profissionais. Tivemos o surgimento de profissões como engenheiros de dados, os cientistas de dados e assim por diante.
E isso foi um marco que resume o ganho de se colocar os dados para funcionar nas organizações. Isso já está bem consolidado. Já temos um data lake com tecnologia Hive e cargas batch.
A maioria das empresas seguiu essa tendência. Temos então a ingestão com códigos e a adoção de Python. Mas tudo isso ainda estão em processamento, mas em evolução constante.
O foco está nos dados. Ainda temos muito esforço manual para lidar como o dado. Ainda temos muito problema para colocar em produção. O algoritmo funciona no teste, mas quando vai para produção acaba não sendo tão seguro e eficiente. Ainda temos muito problema nesse sentido.
Ainda temos problema para colocar em data lake os dados. Não temos, ainda, um bom nível de governança. E isso é uma oportunidade para colocar o modelo de governança que já existe para o Big Data.
Para o futuro, temos um mundo voltado para os dados, tudo em nuvem e ciência de dados em produção. Portanto, uma ciência de dados com uma velocidade muito maior. Agora vamos analisar como ocorreu esse processo no Brasil.
1.2 Evolução da Big Data Science no Brasil
O mercado de Data Science está bem aquecido no Brasil. É um mercado ainda muito pequeno. O país possui menos cientistas de dados do que há em pequenas regiões dos Estados Unidos da América (EUA). No Brasil, por exemplo, a formação ainda é muito diferente. No exterior, o mercado é bem mais competitivo, onde é mais comum termos cientistas de dados com doutorado ao passo que no Brasil, isso é bem mais difícil de ocorrer.
A essência é saber programar. É um passo relevante que fortalece o cientista de dados para o mercado de trabalho que é muito promissor no Brasil. Vamos analisar como estão os postos de trabalho ao compreender as hard e soft skills que o mercado tem requerido dos empregados.
1.3 Avanço da Big Data Science nos postos de trabalho
Faça uma comparação do nível de estudo para conseguir um emprego antigamente e atualmente. Cada vez mais é preciso estudar, adquirir conhecimento. Se você não quer seu trabalho roubado por um robô, você não pode trabalhar como um robô. E hoje, muitos trabalhos estão automatizados.

Fonte: Plataforma Delinea (2022)
a imagem representa uma pessoa que está com o pensamento mecanizado.
Sabemos que as máquinas já substituíram diversos empregos e a tendência é tudo ser ainda mais automatizado. Porém, a questão de inovação e adaptação volta a ser pauta: coisas, produtos e serviços novos surgirão.
Cada vez mais o mercado de trabalho conta com profissionais com mais sede de conhecimento e força de vontade. O ser humano precisará ser capaz de encarar o novo para se encaixar no mercado de trabalho (WB, 2018). Observe que, para você ficar “no jogo” é importante ter inteligência emocional e social, sabendo lidar com as incertezas e mudanças. Além de, claramente ter força de vontade para agir.
A fábrica inteligente tem por marca o aprofundamento da digitalização e da convergência tecnológica, responsáveis por transformar radicalmente as interações entre máquinas, entre pessoas e máquinas e entre as próprias pessoas (LACERDA, 2021). Isso muda não só os processos produtivos em si, mas também, altera a forma de recrutamento e capacitação continuada dos trabalhadores.
Estamos em uma era resumida em exigências dos mercados consumidores. Para isso, é preciso investir cada vez mais em estratégias, tecnologias e inteligência. Nesse contexto, o desenvolvimento de soft skills e hard skills garantem um desempenho melhor, além de ajudar quem já tem um emprego e almeja crescer na carreira. Vamos nos atentar para os conceitos a seguir listados.
Hard Skill
é o conjunto de habilidades técnicas e objetivas, as quais são normalmente as habilidades para ocupantes de determinados cargos dentro de uma profissão. É algo intuitivo, que você faz quase que sem pensar. Essa habilidade pode ser obtida em vários momentos da vida profissional, sendo avaliada por testes ou avaliações de conhecimentos. Podemos ver um exemplo claro da hard skill ao ler um currículo: são o caráter técnico descrito em tópicos, como a formação acadêmica, o nível de especialização e a experiência profissional.

Fonte: Plataforma Delinea (2022)
a imagem representa um curriculum vitae, onde constam as habilidades listadas da pessoa.
Soft Skill
é o conjunto de habilidades interpessoais, sociais, de comunicação, traços de caráter, atitudes, atributo de carreira, inteligência social e emocional. São os atributos que podem ser desenvolvidos. Está relacionado à liderança, abrangendo a comunicação e a capacidade de convivência social. Essas habilidades se emergem, ao lado das hard, como fundamentais. Historicamente, não são aprendidas formalmente nos universos educativos institucionalizados existentes, mas tendem a se tornar cada vez mais parte dos currículos. Alguns exemplos são a criatividade, o pensamento crítico, a comunicação, o trabalho em equipe e a liderança.

Fonte: Plataforma Delinea (2022)
a imagem representa uma pessoa pensando fora da curva, criando algo.
Atente-se, a seguir, para uma tabela com um resumo das diferenças entre hard e soft skills.
Agora, vamos estudar um pouco sobre Data Literacy. Vamos lá!
2. Data Literacy
Data Literacy é a habilidade de transformar os dados em informação. Cada vez mais está presente no mundo do trabalho, a necessidades de possuir habilidade de lidar com os dados. Isso significa que o professional vai precisar lidar com a leitura, a análise, a argumentação e, portanto, tomar a decisão baseada em dados.
Vamos aprofundar os nossos conhecimentos! Vamos lá!
2.1 Definição de Data Literacy
Mesmo que possamos ver que há uma importância crescente para a compreensão das informações que os dados podem nos fornecer, ainda sofremos com o que pode ser chamado de analfabetismo digital. Segundo a reportagem de Alan Zilioti:
“Em toda história, a humanidade tomou decisões com base numa parte do todo, na amostragem, na pesquisa, na estimativa. Agora pela primeira vez, podemos começar a tomar decisões com base no todo, com 100% da informação. Essa reflexão foi feita pelo professor Michael Malone, da Universidade Santa Clara (Vale do Silício) e nunca fez tanto sentido como diante do momento que estamos vivendo.”

Fonte: Portal ItForum. Disponível em: https://itforum.com.br/noticias/o-que-e-data-literacy-e-por-que-ele-e-cada-vez-mais-importante-para-o-negocio/. Acesso em 23 mai 2022.
A imagem apresenta uma reportagem intitulada “O que é Data Literacy e por que ele é cada vez mais importante para o negócio?”.
Agora vamos estudar a contextualização de Data Literacy no Brasil. Vamos lá!
2.2 Contextualização de Data Literacy no Brasil
A cada dia que passa a quantidade de dados se multiplica para não falar que se quadruplica. E um ponto chave para isto, é que possamos ter uma mesma linguagem para falar sobre os dados. Precisamos transformar o dado em informação.

Fonte: Plataforma Delinea (2022)
a imagem representa uma cabeça que representa um robô.
Existe um processo e isso significa que existe uma forma para se ler, criar e arqumentar com os dados. E a alfabetização é relevante para que este processo leve você a fazer com que a sua empresa seja guiada por dados também (PADILHA ET AL, 2022). Isso é uma construção consistente e com visão para o futuro.
Então data literacy e data driven são conceitos que, quando incorporados, vão fazer com que a sua empresa tome as decisões com menos empirismo (achismo) e com mais orientação em dados. Existe um costume, ainda, da maioria dos gestores de se tomar a decisão sem ser orientada a dados. Isso acontece por falta de tempo, mão de obra qualificada, processos engessados. Enfim, falta uma cultura orientada a dados.
2.3 Impacto da Data Literacy para a Big Data Science
Nos anos que se seguirem, acontecerá o aumento da concorrência no mundo do trabalho, principalmente em razão da diminuição dos números de vagas abertas devido à recessão econômica (WB, 2018).
Nesse sentido, observamos que as habilidades relacionadas com Big Data, Data Science são formas essenciais de hard skills para aqueles que desejam prosperar. E a data Literacy é uma forma de conectar as necessidades das empresas com o desejo de obter um emprego promissor.

Fonte: Plataforma Delinea (2022)
a imagem representa a foto de uma mulher que está em uma sala com outras pessoas, realizando uma prova de conhecimentos.
Uma alternativa é ampliar os conhecimentos em cursos de extensão ou estudar temas mais práticos da área profissional desejada, aproveitando o bom momento do ensino a distância para ampliar as hard skills. Investir em soft skill é válido, já que a empatia, a criatividade e a inteligência emocional são habilidades que ajudarão o candidato a enfrentar o mundo do trabalho (WEF, 2020).
Se há pouco tempo, os critérios para avaliação dos candidatos eram resumidos à análise da formação acadêmica e experiência prática, hoje as outras habilidades relacionadas às soft skills terão ainda mais espaço e destaque.

Fonte: Plataforma Delinea (2022)
a imagem representa a foto de uma cliente e de uma atendente em uma padaria.
Então já podemos perceber que as hard skills também não ficarão para trás em termos de exigências já que não será mais aceito profissionais que não possuem este tipo de habilidade. Se você é um advogado, ou um médico, ou um contador (e assim por diante) e sabe programar, você está em vantagem em relação aos demais.
Portanto, carreiras relacionadas à tecnologia e isso inclui fundamentalmente aquelas que exigem habilidades relacionadas com Big Data, precisam desenvolver a sua data literacy.
Vamos, agora, estudar os principais conceitos relacionados com Big Data Science. Vamos lá!
3. Principais conceitos em Big Data Science
Temos alguns conceitos que são relevantes dentro da Data Science. Sem eles fica complicado evoluirmos nos nossos estudos. Neste momento, vamos compreender os conceitos relacionados com Banco de Dados. Vamos lá!
3.1 Conceitos relacionados com Banco de Dados
Os bancos de dados e aplicações de processamento tradicionais não conseguem absorver este volume enorme de informações de dados. Então, nos últimos anos, foram sendo desenvolvidas alternativas possíveis e melhores para que toda essa informação faça sentido e para que possamos extrair conhecimento e novas estratégias desse novo mundo de dados.
Atente-se a seguir para a notícia, a qual aponta a importância crescente que a ciência de dados possui para o desenvolvimento do conhecimento.

Fonte: Jornal da USP.
Disponível em: https://jornal.usp.br/atualidades/ciencia-de-dados-e-disciplina-chave-para-desenvolver-conhecimento/. Acesso em 23 mai 2022.
a imagem representa a foto uma reportagem do jornal da USP intitulada “Ciência de Dados é disciplina-chave para desenvolver conhecimento”.
Antes de nós avançarmos no mundo do data science, seria importante definirmos a matéria-prima desse mundo: a informação, o dado e o conhecimento. Para Amaral (2018, p.5):
Dados são fatos coletados e normalmente armazenados. Informação é o dado analisado e com algum significado. O conhecimento é a informação interpretada, entendida e aplicada para um fim.
O dado pode ser obtido de forma analógica ou digital ou, ainda, não eletrônico que seria o dado que está no papel. Já o dado analógico é transmitido por ondas e pode sofrer interferências eletromagnéticas (SANTOS ET AL, 2021). Já o dado digital é aquele transmitido em pacotes de bits e essa forma é a mais eficiente. No campo da ciência de dados, apesar de estudarmos os dados em geral, estamos focados no dado no formato digital.

Fonte: Plataforma Delinea (2022)
a imagem representa a foto de diversos itens de um escritório inovador: tablet, relógio, smartphone, mouse sem fio, óculos, calculadora entre outros.
Vamos, agora, para outra definição que é de data science.
Curiosidades
Science ou ciência de dados é a ciência que, segundo Amaral (2018), trata de obter conhecimento e informação de maneira constante a todo momento. Mas também, é uma ciência que organiza as informações. Informação sem organização e sistematização não faz muito sentido.
Então temos o dado, precisamos armazená-lo, depois processá-lo. Essa etapa pode significar uma transformação. Por exemplo, temos as informações das notas fiscais, certo? Para chegar em um banco de dados, será necessária uma transformação. Pronto. Agora já temos o dado produzido, armazenado e transformado.
Outro ponto relevante a ser esclarecido são os tipos de dados que podemos encontrar na literatura de ciência de dados: contínuo, categórico e ordinal. Isso é relevante, pois com essa informação podemos escolher adequadamente a técnica e o software para processar os dados.
Os dados contínuos podem assumir qualquer valor em um intervalo. Então, se colocarmos em um gráfico a quantidade de areia em uma praia ao longo do tempo, assumiremos que essa pergunta possui uma resposta que não poderemos dar sem considerarmos um intervalo de dados, pois os dados são contínuos. Não haverá um intervalo certinho para cada período, por isso, informamos que nesse caso, há uma aproximação da quantidade de areia.
Outro termo utilizado é dados discretos. Estes dados podem assumir apenas valores inteiros que normalmente podemos contar. Quando você participa de um bingo, está ouvindo dados discretos. Não há aproximação nos valores. E, ainda, há um intervalo entre cada valor informado.
Os dados categóricos são aqueles que podem assumir apenas um conjunto específico de valores representando um conjunto de possíveis categorias. Utilizamos dados categóricos para definir uma quantidade de pessoas por escolaridade, por exemplo. Nesse caso, quero saber quantas pessoas existe por nível de escolaridade.
Os dados binários são um tipo especial de dados categóricos, pois apresentam apenas duas categorias. Exemplos são 0 ou 1 ou, ainda, verdadeiro ou falso. Os dados ordinais também são um tipo de dado categórico, porém o dado possui uma ordem explícita. É o caso da escolaridade de um grupo de pessoas, pois é mais coerente que a informação seja ordenada da menor escolaridade para a maior e assim por diante.
Resumindo, temos os tipos de dados conforme a tabela abaixo.
Para Bruce e Bruce (2019), é importante sabermos a taxonomia dos tipos de dados para que possamos realizar a análise dos dados e a modelagem preditiva.
Como assim?
Veja que para poder determinar o tipo de exposição visual precisamos entender com qual dado estamos trabalhando. O tipo de dado determina como o software que utilizarão processará os cálculos para a variável estudada.
Agora é interessante diferenciar estatística ou análise estatística de ciência de dados. A análise de dados estatística é apenas uma das etapas da ciência de dados que engloba todo o ciclo de vida do dado.
Atenção
A ciência de dados com um ramo que envolve, segundo Amaral (2018), um ciclo de vida completo e não apenas o processamento das informações que vemos com muita frequência em estatística. Por isso, inclusive, confundimos muito análises estatísticas com ciência de dados. O dado possui um ciclo de vida.
E como isso acontece?
Ao nascer, o dado no formato digital produzido por algum dispositivo digital é como se fosse uma foto. E essas fotos são tiradas a todo momento. Mas sem que seja processado jamais conheceremos a foto. Contudo, antes disso, precisamos armazenar essas informações.
Atenção
Qual o formato do dado? Se você quer abrir um arquivo que contém informações, precisa usar o software adequado para cada tipo de situação. Podemos ter dados em texto, em XML, em um banco de dados relacional e assim por diante.
Então já estamos vendo uma série de pontos que são relevantes no estudo da ciência de dados. Vamos, agora, estudar a diferença entre Big Data, Data Science e Machine Learning. Vamos lá!
3.2 Diferença entre Big Data, Data Science e Machine Learning
Um termo que é usualmente utilizado para esse mundo de informações é big data. Além disso, é uma das definições mais relevantes é o de big data.
Mas o que seria big data?
Saiba mais
Big data é o conjunto de dados extremamente amplo que exige ferramentas especiais para processar esses dados em tempo hábil. De forma mais simples, é a análise de grandes conjuntos de dados para gerar valor para o negócio.
O termo big data popularizou-se, nos últimos anos, devido ao impulsionamento do uso de ferramentas tecnológicas que geram um grande volume de dados (PADILHA ET AL, 2021). As mídias sociais são uma das principais fontes de informações em tempo real.
Mas os usos e as fontes são amplos e vão muito além disso. O conceito de big data foi impulsionado pelo analista Doug Laney nos anos 2000. Esse autor definiu big data em três Vs: volume, velocidade e variedade.
O volume está relacionado com o tamanho dos dados. Pode ser uma grande quantidade de arquivos pequenos ou mesmo grandes arquivos. A velocidade está relacionada à geração de dados.
E variedade está relacionado ao formato dos dados. Os dados são gerados em inúmeros formatos que podem ser divididos em formato estruturado e em formato não estruturado.
Fonte: Plataforma Delinea (2022)
a imagem representa símbolos relacionados com a tecnologia e com transporte.
Os dados estruturados geralmente são armazenados em tabelas de bancos de dados. E o formato de dados não estruturados são textos, e-mails, vídeos e áudios.
Ainda temos os dados em formato semi-estruturado: são os dados que, apesar de não estarem em bancos de dados, possuem marcações ou tags que dão a indicação semântica dos dados. Geralmente são disponibilizados em formato xml e json.
Até o momento, vimos os conceitos de ciência de dados ou, em inglês, Data Science. Porém, no nosso dia a dia, temos outros conceitos que são empregados com relativa frequência: inteligência artificial (IA) e machine learning ou, em inglês, aprendizado de máquina. Vamos agora diferenciar esses dois conceitos.
Atente-se para o diagrama a seguir, o qual poderá esclarecer como a terminologia de ciência de dados é utilizada em nosso dia a dia. Perceba que data Science é um dos campos de inteligência artificial.
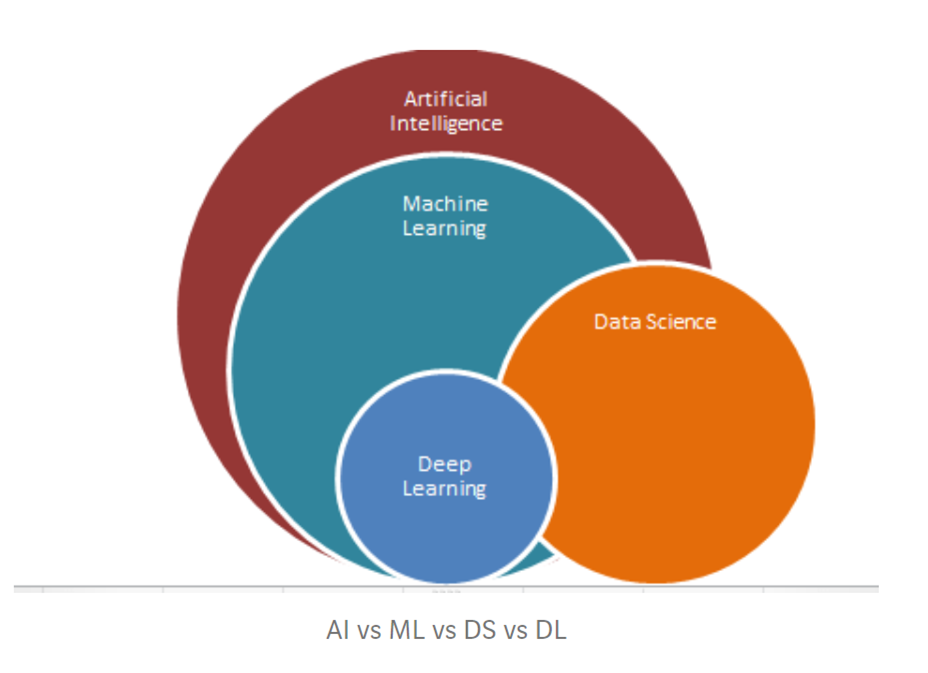
Fonte: Revista Becoming Human.
Disponível em: https://becominghuman.ai/ultimate-guide-and-resources-for-data-science-2019-f663f9384fc7. Acesso em 23 mai 2022.
a imagem representa uma imagem que indica a abrangência da inteligência artificial, machine learning, data Science e deep learning.
Assim como aprendizado de máquinas pode ser utilizado pela ciência de dados bem como pelo deep learning e faz parte do grande mundo da inteligência artificial.
Reflita
Mas o que seria a inteligência artificial?
Pontes (2011) nos diz que a Inteligência Artificial é uma área de pesquisa que se dedica a buscar métodos ou dispositivos computacionais que possuam ou simulem a capacidade racional humana de resolver problemas, tomada de decisões ou, de forma ampla, ser inteligente.
Essa área do conhecimento começou a ser desenvolvida logo após a Segunda Guerra Mundial por meio do cientista Alan Turing com o artigo “Computing Machinery and Intelligence”. Já o termo propriamente dito “Inteligência Artificial” foi estabelecido em 1956 durante um workshop de cientistas da computação em Dartmouth nos Estados Unidos.
A partir disso, podemos aprofundar o nosso estudo sobre Inteligência Artificial e pensar que tudo que é previsível é rastreável e, portanto, pode ser substituído por um algoritmo.
Isso já nos dá uma noção da abrangência que esse campo do conhecimento irá ter nas nossas vidas. Precisamos, portanto, focar a nossa aquisição de conhecimento em atividades que envolvam o pensamento de tarefas não repetitivas. Veja que com isso podemos perceber que a Inteligência Artificial já é o nosso presente.
Curiosidades
Para Pierson (2015, p.15), a definição de aprendizado de máquina é:
Aprendizado de máquina é a prática de aplicar modelos algorítmicos em dados de maneira iterativa, ou seja, repetitiva, para que o seu computador descubra padrões ou tendências ocultas que você pode usar para fazer previsões. Ela também é chamada de aprendizado algorítmico.
Como isso funciona na prática?
Uma coisa comum para todo algoritmo de aprendizado é a necessidade de dados, certo? Por isso, passamos um tempinho descrevendo os tipos de dados e a sua forma de estruturação. O dado funciona como um combustível para carro para o cientista de dados.
Estão intimamente relacionados. Atente-se para o exemplo, a seguir, para materializar esse conceito.
2-4
8-16
9-18
10-20
25-50
50-?
Qual será o próximo número?
100, ok?
Por que inferimos que esse seria o resultado?
Fomos aprendendo com a série de dados colocada e, então, aprendemos que o próximo número seria 100. É assim que o aprendizado de máquinas ocorre na prática. Essa é a sua lógica de funcionamento: Identificar um padrão para o fenômeno que o dado apresentou.
O algoritmo é treinado pelos dados para depois ser capaz de prever com alto nível de acurácia os novos resultados. Alguns dos algoritmos mais famosos são classificação, regressão, agrupamento e deep learning.
O objetivo primordial do aprendizado de máquina é generalizar o padrão encontrado no treinamento dos dados (SANTOS ET AL, 2021). Um bom modelo deve ser capaz de observar dados de entrada e modelar o fenômeno de uma forma nem muito genérica e nem muito específica.
Isso é relevante, pois se for genérico demais, as previsões serão tão boas quanto um chute aleatório, e se específico demais, o modelo terá decorado os dados de entrada e não saberá como lidar com novos dados de entrada. Isso é chamado de generalização.
Assim, podemos dizer que uma necessidade basilar é a manipulação de dados. Porém, para Pierson (2019, p.25), precisamos seguir um passo a passo para preparar os dados para a análise de dados.
o 1. Importe. Leia atentamente os conjuntos de dados relevantes em seu aplicativo.
o 2. Limpe. Remova os registros isolados, duplicados e fora da caixa e padronize as letras maiúsculas e minúsculas.
o 3. Transforme. Nessa etapa, você deve tratar os valores ausentes, lidar com os atípicos e dimensionar suas variáveis.
o 4. Processe. Processar seus dados envolve a análise deles, recodificação das variáveis, concatenação e outros métodos de reformatação de seu conjunto de dados para prepara-los para a análise.
o 5. Registre. Nessa etapa, você deve apenas criar um registro que descreva seu conjunto de dados. Esse registro deve incluir a estatística descritiva, informações sobre os formatos da variável, fonte dos dados e métodos de coleta, entre outros itens. Assim que você gerar esse registro, armazene-o em um lugar fácil de lembrar para o caso de precisar compartilhar esses detalhes com os outros usuários do conjunto de dados processado.
o 6. Faça um backup. A última etapa da preparação dos dados é fazer um backup do conjunto de dados processado para dispor de uma versão limpa e atual qualquer que seja.
Assim queremos encontrar padrões nos dados e, com isso, transmitir aos diversos usuários informações em formato de conhecimento. Isso é possível com a concatenação de ideias extraídas das inferências dos dados. Desse modo, o cientista de dados deve ter habilidades de comunicação oral e escrita bem estruturadas.
Se você pretende ser um cientista de dados, então necessita comunicar-se com avidez e de maneira convincente. Você será a pessoa responsável por transmitir conhecimento e informação no mundo e sem a sua arguição de nada valerá o esforço em manipular os dados.
Portanto, os cientistas de dados precisam conseguir explicar as informações de dados de um modo que os membros da equipe possam entender de maneira simples e objetiva. Ademais, precisam também, conseguir produzir relatórios para que os dados sejam visualizados adicionado de narrativas escritas convincentes e significativas.
Para Pierson (2015), as pessoas precisam ver algo por si mesmas para poderde fato, compreender as informações. Desse modo, a criatividade é um atributo presente constantemente em um cientista de dados. O pragmatismo e o domínio dos métodos de comunicação são outros atributos que devem estar presentes em um bom cientista de dados.
Atenção
Então, veja a seguir alguns exemplos dos usos do aprendizado de máquina apresentados por Pierson (2019, p.32):
- Usar aprendizagem de máquina para otimizar os usos da energia solar e reduzir as pegadas de carbono corporativas.
- Otimizar estratégias para conseguir os objetivos nos negócios e na ciência.
- Prever níveis de contaminação desconhecidos a partir de conjuntos de dados ambientais esparsos.
- Planejar sistemas automatizados de prevenção contra roubo e fraude para detectar anomalias e disparar alarmes com base em resultados algorítmicos.
- Construir mecanismos de recomendação de sites para usar nas aquisições de terras e desenvolvimento de bens imobiliários.
- Implementar e interpretar a análise preditiva e técnica de previsão para a ampliação do valor de negócio resultante.
Por fim, agora vamos conhecer os principais instrumentos de Data Science.
3.3 Principais instrumentos de Big Data Science
Data science possui os mais diversificados instrumentos. Como é uma habilidade que exige a manipulação com dados, então você vai precisar se valer de instrumentos para chegar até o resultado desejado. Isso inclui aprender a manipular ferramentas como o Excel, PowerBI, RStudio, Python e assim por diante.
A análise de dados é uma das áreas mais conhecidas em Big Data. Podemos usar SQL para visualizar os dados de vendas, por exemplo. Para isto, você pode se valer de aplicações como o RStudio e o Python para analisar os dados e obter informações úteis para o nosso dia a dia.
Após isso, temos a finalidade de visualizar o nosso dado para um usuário final que pode variar grandemente a depender do contexto em que estamos inseridos. Isso significa que pode ser apropriado que você utilize o Excel, por exemplo. Esse tipo de avaliação é preciso ser feita.
Em algum momento, será a hora de descartar o dado já que o seu ciclo de vida terminou.
Considerações Finais
Percebe-se que Data Science é uma área promissora e que requer conhecimento técnico especializado. Como vimos, é considerada hoje uma área relevante já que o dado é o novo petróleo das empresas. Funciona essencialmente como uma nova linguagem que o profissional vai precisar lidar.
A expansão tem sido tão proeminente que áreas que não exigiam data Literacy agora já enxergam os conhecimentos em data Science como uma habilidade que o diferencia e, até mesmo, que sustenta o profissional no mundo do trabalho.
Na aula de hoje, você estudou e aprendeu:
- a contextualizar a Big Data Science;
- o conceito de Data Literacy;
- os principais conceitos relacionados com Big Data Science.
Resumo da Unidade
Agora que você concluiu a leitura do conteúdo. assista a seguir a videoaula com o resumo da unidade: